Java进阶指南
表达式解析
UEL 统一表达式语言
Ognl 对象图导航语言
Spel Spring表达式语言
Java 进阶
SPI的高级用法
SLF4J的绑定原理
H2 JDBC驱动类注册与数据库引擎初始化原理
Java SPI与Dubbo SPI区别
Java 秒懂对象 PO、VO、BO、DTO、POJO!
Java POJO/DO/DTO/BO/VO概念及应用案例分析
一个线程oom,进程里其他线程还能运行吗?
jps命令详解
Java的BigDecimal也会存在丢失精度的问题
java中的枚举类和常量类区别在哪儿?
Java 打包 FatJar 方法小结
"too many open files"的原理和解决方案
GraalVM 专栏
GraalVM入门以及环境搭建
Maven 专栏
maven 跳过单元测试-maven.test.skip和skipTests的区别
maven 配置代码检查插件,生成检查报告
Maven 执行生命周期
maven 删除本地仓库当前项目的依赖包
Gradle 专栏
自己动手应用Groovy实现Gradle的DSL—Task定义
看懂Gradle脚本(1)- Groovy语言的Map语法糖
看懂Gradle脚本(2)- Groovy语言的闭包语法
看懂Gradle脚本(3)- Groovy AST转换
看懂Gradle脚本(4)- Groovy语法之运算符重载
看懂Gradle脚本(5)- 跟Gradle学领域驱动设计
看懂Gradle脚本(6)- Hello Groovy, Goodbye Getters&Setters
看懂Gradle脚本(7)- ext {}函数是如何实现的
Gradle 常见问题集锦
Spring 专栏
Spring AOP 使用介绍,从前世到今生
Spring IOC 容器源码分析
Spring AOP 源码解析
Spring @PropertySource 注解实现读取 yml 文件
Spring 好用的工具类
Spring @Async失效情况
Spring I/O 2023 干货视频精选!
Spring 动态刷新bean
Spring Cache缓存技术
Spring @Transactional注解失效情况
Spring Event 事件订阅踩坑
循环依赖
Spring 解析@Async引起的循环依赖
Spring 中的循环依赖
从源码层面深度剖析 Spring 循环依赖 | 京东云技术团队
Spring 不同平台构建出现循环依赖错误问题原因分析
SpringBoot 专栏
SpringBoot 构建FarJAR Maven配置
SpringBoot 项目启动慢原因分析
SpringBoot 资源文件问题总结(Spring Boot的静态资源访问,配置文件外置)
SpringBoot 读取Jar包中静态资源原理
SpringBoot 配置Undertow处理高并发
SpringBoot Maven Profile配合Spring Profile进行多环境配置和打包
SpringBoot 使用profile结合maven实现多环境配置
SpringBoot @ComponentScan注解过滤排除不加载某个类的3种方法
Mybatis 专栏
Mybatis 一级、二级缓存机制
Mybatis 关闭一级、二级缓存机制
MybatisPlus
MybatisPlus LambdaQueryWrapper类的实现原理
MybatisPlus 在不修改全局策略和字段注解的情况下将字段更新为null
并发与多线程
Java 从单核到多核的多线程并发
并发和并行的区别
Redisson 专栏
一次生产redisson 延时队列不消费问题排查
redisson 阻塞队列不消费问题排查
Spring Batch 专栏
批处理框架spring batch基础知识介绍
Shiro 专栏
一篇适合小白的Shiro教程
SpringMVC 专栏
SpringMVC 后端处理多文件上传如何保持最大的灵活性
@RequestParam的加与不加的作用
SpringCloud 专栏
Gateway 一文彻底解决跨域问题
ruoyi-vue-pro 开发指南
萌新必读
简介
交流群
视频教程
功能列表
快速启动(后端项目)
快速启动(前端项目)
接口文档
技术选型
项目结构
代码热加载
一键改包
删除功能
内网穿透
达梦数据库专属
后端手册
新建模块
代码生成【单表】(新增功能)
代码生成【主子表】
代码生成【树表】
功能权限
数据权限
用户体系
三方登录
OAuth 2.0(SSO 单点登录)
SaaS多租户【字段隔离】
SaaS 多租户【数据库隔离】
WebSocket 实时通讯
异常处理(错误码)
参数校验、时间传参
分页实现
VO 对象转换、数据翻译
文件存储(上传下载)
Excel 导入导出
操作日志、访问日志、异常日志
MyBatis 数据库
MyBatis 联表&分页查询
多数据源(读写分离)、事务
Redis 缓存
本地缓存
异步任务
分布式锁
幂等性(防重复提交)
请求限流(RateLimiter)
单元测试
验证码
工具类
配置管理
数据库文档
中间件手册
定时任务
消息队列(内存)
消息队列(Redis)
消息队列(RocketMQ)
消息队列(RabbitMQ)
消息队列(Kafka)
限流熔断
工作流手册
工作流演示
功能开启
工作流(达梦适配)
审批接入(流程表单)
审批接入(业务表单)
流程设计器(BPMN)
流程设计器(钉钉、飞书)
选择审批人、发起人自选
会签、或签、依次审批
流程发起、取消、重新发起
审批通过、不通过、驳回
审批加签、减签
审批转办、委派、抄送
执行监听器、任务监听器
流程表达式
流程审批通知
大屏手册
报表设计器
大屏设计器
支付手册
功能开启
支付宝支付接入
微信公众号支付接入
微信小程序支付接入
支付宝、微信退款接入
会员手册
功能开启
微信公众号登录
微信小程序登录
会员用户、标签、分组
会员等级、积分、签到
商城手册
商城演示
功能开启
商城装修
【商品】商品分类
【商品】商品属性
【商品】商品 SPU 与 SKU
【商品】商品评价
【交易】购物车
【交易】交易订单
【交易】售后退款
【交易】快递发货
【交易】门店自提
【交易】分销返佣
【营销】优惠劵
【营销】拼团活动
【营销】秒杀活动
【营销】砍价活动
【营销】满减送
【营销】限时折扣
【营销】内容管理
【统计】会员、商品、交易统计
ERP手册
ERP 演示
功能开启
【产品】产品信息、分类、单位
【库存】产品库存、库存明细
【库存】其它入库、其它出库
【库存】库存调拨、库存盘点
【采购】采购订单、入库、退货
【销售】销售订单、出库、退货
【财务】采购付款、销售收款
CRM 手册
CRM 演示
功能开启
【线索】线索管理
【客户】客户管理、公海客户
【商机】商机管理、商机状态
【合同】合同管理、合同提醒
【回款】回款管理、回款计划
【产品】产品管理、产品分类
【通用】数据权限
【通用】跟进记录、待办事项
公众号手册
功能开启
公众号接入
公众号粉丝
公众号标签
公众号消息
自动回复
公众号菜单
公众号素材
公众号图文
公众号统计
系统手册
短信配置
邮件配置
站内信配置
数据脱敏
敏感词
地区 & IP 库
运维手册
开发环境
Linux 部署
Docker 部署
Jenkins 部署
HTTPS 证书
服务监控
前端手册 Vue 3.x
开发规范
菜单路由
Icon 图标
字典数据
系统组件
通用方法
配置读取
CRUD 组件
国际化
IDE 调试
代码格式化
前端手册 Vue 2.x
开发规范
菜单路由
Icon 图标
字典数据
系统组件
通用方法
配置读取
更新日志
【v2.1.0】开发中
【v2.0.1】2024-03-01
【v2.0.0】2024-01-26
【v1.9.0】2023-12-01
【v1.8.3】2023-10-24
yudao-cloud 开发指南
萌新必读
简介
交流群
视频教程
功能列表
快速启动(后端项目)
快速启动(前端项目)
接口文档
技术选型
项目结构
代码热加载
一键改包
删除功能
内网穿透
达梦数据库专属
微服务手册
微服务调试(必读)
注册中心 Nacos
配置中心 Nacos
服务网关 Spring Cloud Gateway
服务调用 Feign
定时任务 XXL Job
消息队列(内存)
消息队列(Redis)
消息队列(RocketMQ)
消息队列(RabbitMQ)
消息队列(Kafka)
消息队列(Cloud)
分布式事务 Seata
服务保障 Sentinel
Spring Security 专栏
Spring Security 入门
Spring Security OAuth2 入门
Spring Security OAuth2 存储器
Spring Security OAuth2 单点登录
Spring Security 常见问题
Guava 专栏
Guava 常用API汇总
本文档使用 MrDoc 发布
-
+
首页
Mybatis 一级、二级缓存机制
## 一、MyBatis 缓存 缓存就是内存中的数据,常常来自对数据库查询结果的保存。使用缓存,我们可以避免频繁与数据库进行交互,从而提高响应速度。 MyBatis 也提供了对缓存的支持,分为一级缓存和二级缓存,来看下下面这张图:  `一级缓存` 是 SqlSession 级别的缓存。在操作数据库时需要构造 SqlSession 对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的是 SqlSession 之间的缓存数据区(HashMap)是互相不影响。 `二级缓存` 是 Mapper 级别的缓存,多个 SqlSession 去操作同一个 Mapper 的 sql 语句,多个 SqlSession 可以共用二级缓存,二级缓存是跨 SqlSession 的。 相信大家看完这张图和解释心里应该有个底了吧,这对后面分析 MyBatis 的一级、二级缓存机制很有帮助,那话不多说,我们直接进入主题了。 ## 二、一级缓存 **2.1 内部结构** 在我们的应用运行期间,我们可能在一次数据库会话中,执行多次查询条件相同的 SQL,要你来设计的话你会如何考虑?没错,加缓存,MyBatis 也是这样去处理的,如果是相同的 SQL 语句,会优先命中一级缓存,避免直接对数据库进行查询,造成数据库的压力,以提高性能。具体执行过程如下图所示:  SqlSession 是一个接口,提供了一些 CRUD 的方法,而 SqlSession 的默认实现类是 DefaultSqlSession,DefaultSqlSession 类持有 Executor 接口对象,而 Executor 的默认实现是 BaseExecutor 对象,每个 BaseExecutor 对象都有一个 PerpetualCache 缓存,也就是上图的 Local Cache。 当用户发起查询时,MyBatis 根据当前执行的语句生成 MappedStatement,在 Local Cache 进行查询,如果缓存命中的话,直接返回结果给用户,如果缓存没有命中的话,查询数据库,结果写入 Local Cache,最后返回结果给用户。 啊,老周,关系还是有点抽象,感觉一直在套娃,没关系,看下面这张图你立马豁然开朗。  **2.2 一级缓存配置** 在 MyBatis 的配置文件中添加如下语句,就可以使用一级缓存。共有两个选项,SESSION 或者 STATEMENT,默认是 SESSION 级别,即在一个 MyBatis 会话中执行的所有语句,都会共享这一个缓存。一种是 STATEMENT 级别,可以理解为缓存只对当前执行的这一个 Statement 有效。 STATEMENT 级别粒度更细,我们上面说到,每个 SqlSession 中持有了 Executor,SqlSession 的默认实现类是 DefaultSqlSession,DefaultSqlSession 类持有 Executor 接口对象,而 Executor 的默认实现是 BaseExecutor 对象,每个 BaseExecutor 对象很多方法中都有传 MappedStatement 对象。所有 STATEMENT 级别是针对 SESSION 级别粒度更细的模式。 ``` <setting name="localCacheScope" value="SESSION"/> ``` ## 三、一级缓存实验 下面老周通过几组实验来带你了解 MyBatis 一级缓存的效果,我们首先准备一张简单的表 user,如下: ``` CREATE TABLE `user` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(64) COLLATE utf8_bin DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_bin; ``` 我们在测试类中加上带有 @Before 标注的 before 方法,省得每个单元测试方法都要重复获取 sqlSession 以及 userMapper。 ``` @Before public void before() throws IOException { InputStream resourceAsStream = Resources.getResourceAsStream("SqlMapConfig.xml"); sqlSessionFactory = new SqlSessionFactoryBuilder().build(resourceAsStream); sqlSession = sqlSessionFactory.openSession(true); // 自动提交事务 userMapper = sqlSession.getMapper(UserMapper.class); } ``` **3.1 实验 1** 开启一级缓存,范围为会话级别,调用三次 firstLevelCacheFindUserById,代码如下所示: ``` @Test public void firstLevelCacheFindUserById() { // 第一次查询id为1的用户 User user1 = userMapper.findUserById(1); // 第二次查询id为1的用户 User user2 = userMapper.findUserById(1); System.out.println(user1); System.out.println(user2); System.out.println(user1 == user2); } ``` 控制台日志输出:  我们可以看到,只有第一次真正查询了数据库,后续的查询使用了一级缓存。 **3.2 实验 2** 增加了对数据库的修改操作,验证在一次数据库会话中,如果对数据库发生了修改操作,一级缓存是否会失效。 ``` @Test public void firstLevelCacheOfUpdate() { // 第一次查询id为1的用户 User user1 = userMapper.findUserById(1); System.out.println(user1); // 更新用户 User user = new User(); user.setId(2); user.setUsername("tom"); System.out.println("更新了" + userMapper.updateUser(user) + "个用户"); // 第二次查询id为1的用户 User user2 = userMapper.findUserById(1); System.out.println(user2); System.out.println(user1 == user2); } ``` 控制台日志输出:  我们可以看到,在修改操作后执行的相同查询,查询了数据库,一级缓存失效。 **3.3 实验 3** 开启两个 SqlSession,在 sqlSession1 中查询数据,使一级缓存生效,在 sqlSession2 中更新数据库,验证一级缓存只在数据库会话内部共享。 ``` @Test public void firstLevelCacheOfScope() { SqlSession sqlSession2 = sqlSessionFactory.openSession(true); UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class); System.out.println("userMapper读取数据: " + userMapper.findUserById(1)); System.out.println("userMapper读取数据: " + userMapper.findUserById(1)); // 更新用户 User user = new User(); user.setId(1); user.setUsername("andy"); System.out.println("userMapper2更新了" + userMapper2.updateUser(user) + "个用户"); System.out.println("userMapper读取数据: " + userMapper.findUserById(1)); System.out.println("userMapper2读取数据: " + userMapper2.findUserById(1)); } ``` 控制台日志输出:  sqlSession2 更新了 id 为 1 的用户的姓名,从 riemann 改为了 andy,但 session1 之后的查询中,id 为 1 的学生的名字还是 riemann,出现了脏数据,也证明了之前的设想,一级缓存只在数据库会话内部共享。 ## 四、一级缓存工作流程以及源码分析 **4.1 工作流程** 我们来看下一级缓存的时序图:  **4.2 源码分析** 看完上面的整体时序流程,我相信大家基本框架了解了,接下来针对这个框架再进行源码细化走读。 `SqlSession`:对外提供了用户和数据库之间交互需要的所有方法,隐藏了底层的细节。默认实现类是 DefaultSqlSession。  `Executor`:SqlSession 向用户提供操作数据库的方法,但和数据库操作有关的职责都会委托给 Executor。  如下图所示,Executor 有若干个实现类,为 Executor 赋予了不同的能力。  在一级缓存的源码分析中,主要学习 BaseExecutor 的内部实现。 `BaseExecutor`:BaseExecutor 是一个实现了 Executor 接口的抽象类,定义若干抽象方法,在执行的时候,把具体的操作委托给子类进行执行。 ``` protected abstract int doUpdate(MappedStatement var1, Object var2) throws SQLException; protected abstract List<BatchResult> doFlushStatements(boolean var1) throws SQLException; protected abstract <E> List<E> doQuery(MappedStatement var1, Object var2, RowBounds var3, ResultHandler var4, BoundSql var5) throws SQLException; protected abstract <E> Cursor<E> doQueryCursor(MappedStatement var1, Object var2, RowBounds var3, BoundSql var4) throws SQLException; ``` 在上文有提到对 Local Cache 的查询和写入是在 Executor 内部完成的。在阅读 BaseExecutor 的代码后发现 Local Cache 是 BaseExecutor 内部的一个成员变量,如下代码所示。 ``` public abstract class BaseExecutor implements Executor { ... protected ConcurrentLinkedQueue<BaseExecutor.DeferredLoad> deferredLoads; protected PerpetualCache localCache; protected PerpetualCache localOutputParameterCache; ... } ``` `Cache`:MyBatis 中的 Cache 接口,提供了和缓存相关的最基本的操作,如下图所示:  有若干个实现类,使用装饰器模式互相组装,提供丰富的操控缓存的能力,部分实现类如下图所示:  BaseExecutor 成员变量之一的 PerpetualCache,是对 Cache 接口最基本的实现,其实现非常简单,内部持有 HashMap,对一级缓存的操作实则是对 HashMap 的操作。如下代码所示: ``` public class PerpetualCache implements Cache { private final String id; private Map<Object, Object> cache = new HashMap(); ... } ``` 调研了一下,画出工作流程图:  跟踪到 PerpetualCache 中的 clear() 方法。 ``` public class PerpetualCache implements Cache { ... private Map<Object, Object> cache = new HashMap(); public void clear() { this.cache.clear(); } ... } ``` 也就是说一级缓存的底层数据结构就是 HashMap。所以说 cache.clear() 其实就是 map.clear(),也就是说,缓存其实是本地存放的一个 map 对象,每一个 SqlSession 都会存放一个 map 对象的引用。 那么这个 cache 是何时创建的呢? 根据上面我们画的工作流程,明显在 Executor 执行器,执行器用来执行 sql 请求,而且清除缓存的方法也在 Executor 中执行,去查看源码,果真在里面。 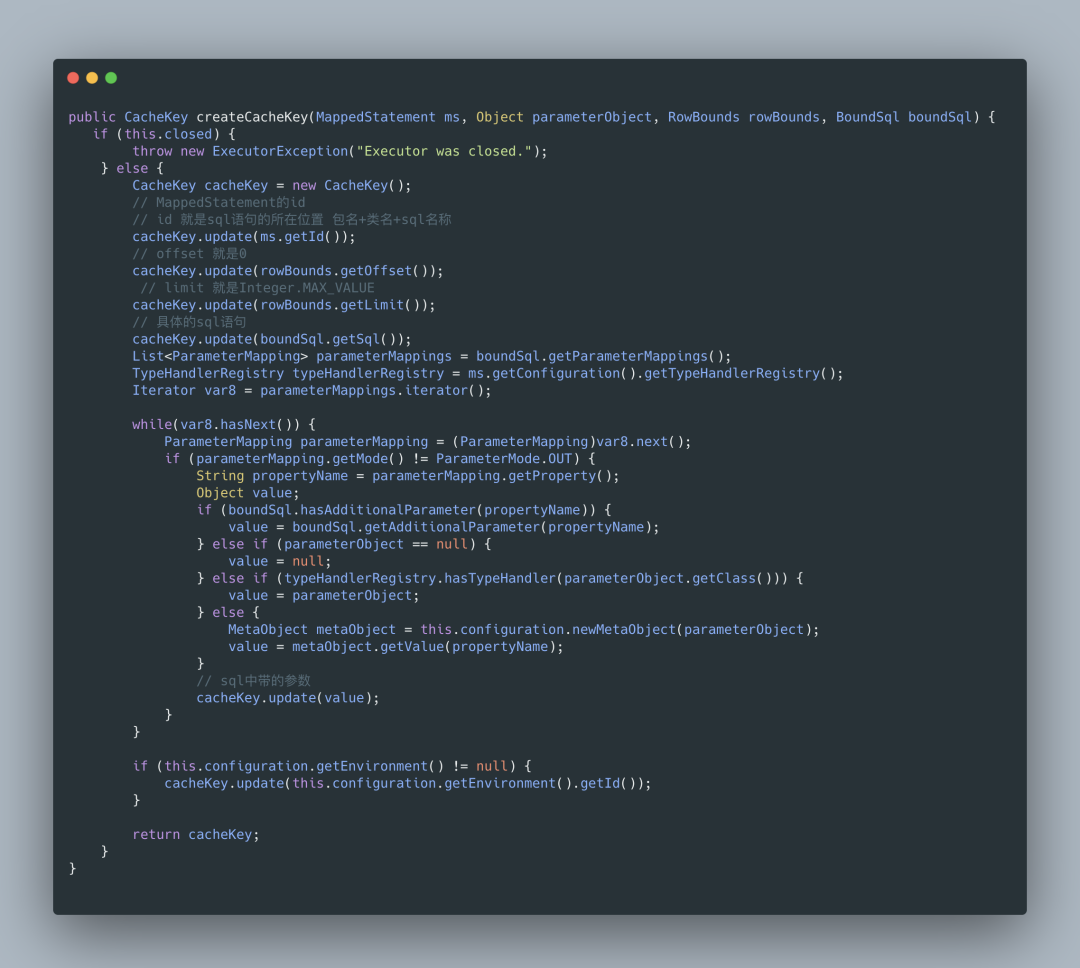 创建缓存 key 会经过一系列的 update 方法,update 方法由一个 cacheKey 这个对象来执行的。这个 update 方法最终由 updateList 的 list 来把六个值存进去,对照上面的代码,你应该能理解下面六个值分别是啥了吧。 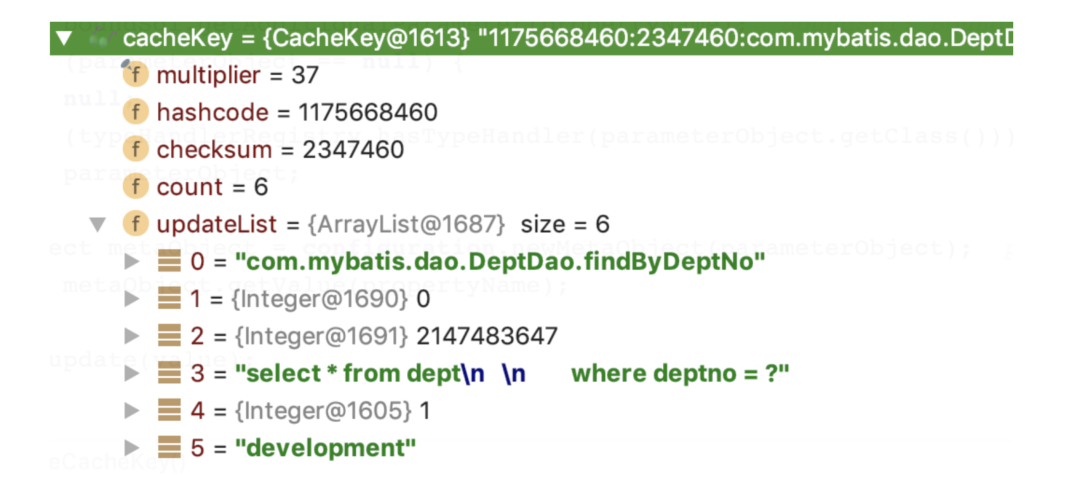 这里需要关注最后一个值 this.configuration.getEnvironment().getId(),这其实就是定义在 mybatis-config.xml 中的标签。如下: 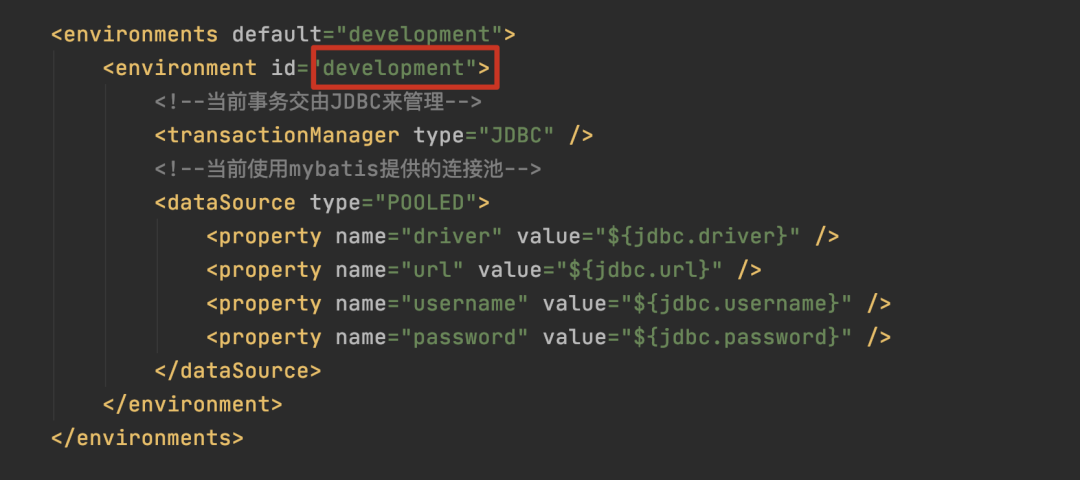 那么问题来了,创建缓存了,那具体在哪里用呢?我们一级缓存探究后,我们发现一级缓存更多的用于查询操作。我们跟踪到 query 方法: 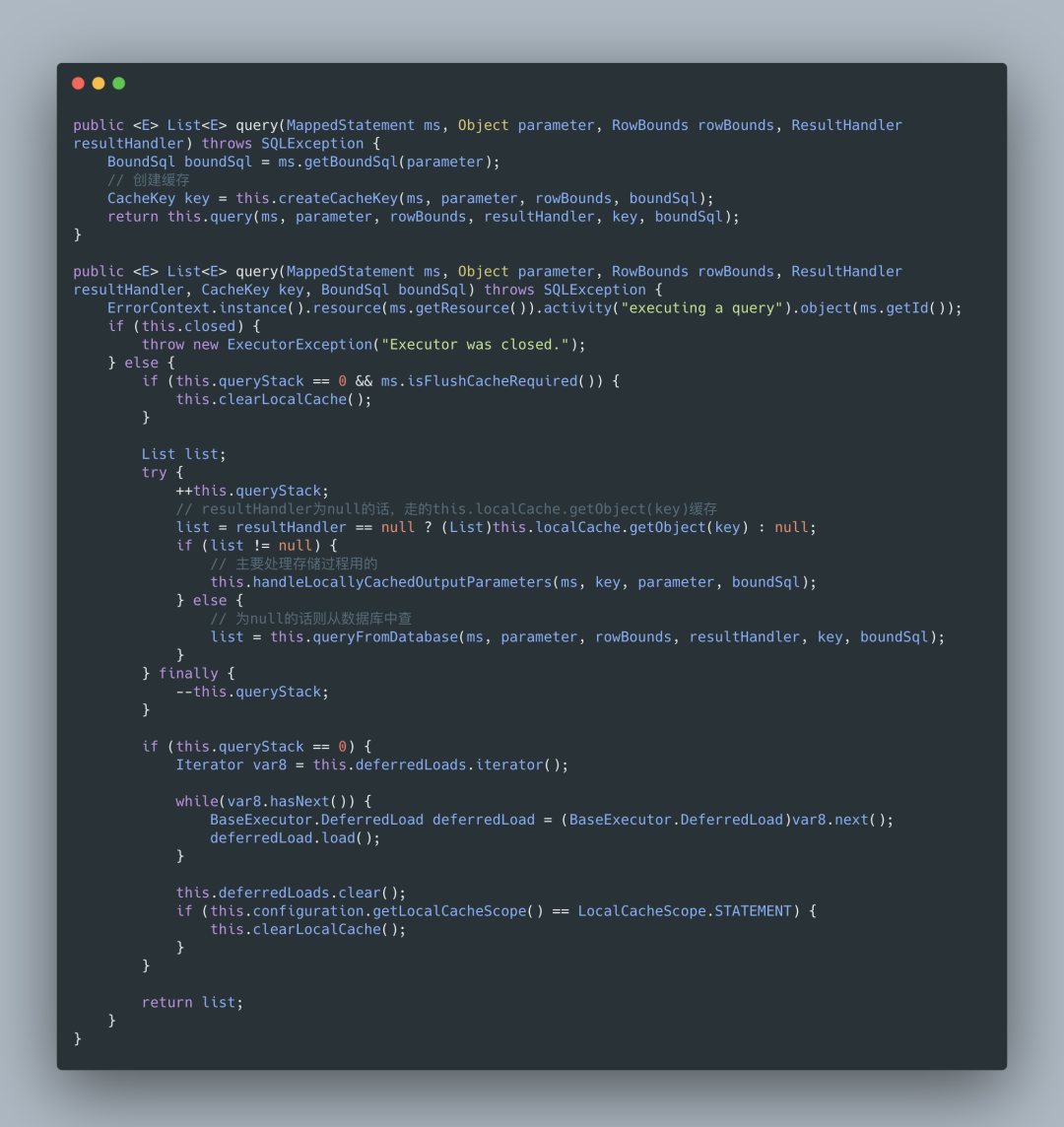 如果查不到的话,就从数据库查,在 queryFromDatabase 中,会对 localcache 进行写入。 在 query 方法执行的最后,会判断一级缓存级别是否是 STATEMENT 级别,如果是的话,就清空缓存,这也就是 STATEMENT 级别的一级缓存无法共享 localCache 的原因。代码如下所示: ``` if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) { clearLocalCache(); } ``` 在源码分析的最后,我们确认一下,如果是 insert/delete/update 方法,缓存就会刷新的原因。 SqlSession 的 insert 方法和 delete 方法,都会统一走 update 的流程,代码如下所示: ``` @Override public int insert(String statement, Object parameter) { return update(statement, parameter); } @Override public int delete(String statement) { return update(statement, null); } ``` update 方法也是委托给了 Executor 执行。BaseExecutor 的执行方法如下所示: ``` @Override public int update(MappedStatement ms, Object parameter) throws SQLException { ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId()); if (closed) { throw new ExecutorException("Executor was closed."); } clearLocalCache(); return doUpdate(ms, parameter); } ``` 每次执行 update 前都会清空 localCache。 至此,一级缓存的工作流程讲解以及源码分析完毕。 ## 五、一级缓存小结 - MyBatis 一级缓存的生命周期和 SqlSession 一致。 - MyBatis 一级缓存内部设计简单,只是一个没有容量限定的 HashMap,在缓存的功能性上有所欠缺。 - MyBatis 的一级缓存最大范围是 SqlSession 内部,有多个 SqlSession 或者分布式的环境下,数据库写操作会引起脏数据,建议设定缓存级别为 Statement。 ## 六、二级缓存 在上文中提到的一级缓存中,其最大的共享范围就是一个 SqlSession 内部,如果多个 SqlSession 之间需要共享缓存,则需要使用到二级缓存。开启二级缓存后,会使用 CachingExecutor 装饰 Executor,进入一级缓存的查询流程前,先在 CachingExecutor 进行二级缓存的查询,具体的工作流程如下所示。  二级缓存开启后,同一个 namespace 下的所有操作语句,都影响着同一个 Cache,即二级缓存被多个 SqlSession 共享,是一个全局的变量。 当开启缓存后,数据的查询执行的流程就是 二级缓存 -> 一级缓存 -\> 数据库。 MyBatis 是默认关闭二级缓存的,因为对于增删改操作频繁的话,那么二级缓存形同虚设,每次都会被清空缓存。 **6.1 二级缓存配置** 和一级缓存默认开启不一样,二级缓存需要我们手动开启。 **6.1.1 首先在全局配置文件 SqlMapConfig.xml 文件中加入如下代码:** ``` <!--开启二级缓存--> <settings> <setting name="cacheEnabled" value="true"/> </settings> ``` **6.1.2 其次在 UserMapper.xml 文件中开启二级缓存** mapper 代理模式: ``` <!--开启二级缓存--> <cache /> ``` 注解开发模式: ``` @CacheNamespace(implementation = PerpetualCache.class) // 开启二级缓存 public interface UserMapper { } ``` mapper 代理模式开启的二级缓存是一个空标签,其实这里可以配置,PerpetualCache 这个类是 mybatis 默认实现的二级缓存功能的类,我们不写 type ,用 @CacheNamespace 直接默认 PerpetualCache 这个类,也可以去实现 Cache 接口来自定义缓存。  **6.2 实体类实现 Serializable 序列化接口**  开启二级缓存后,还需要将要缓存的实体类去实现 Serializable 序列化接口,为了将缓存数据取出执行反序列化操作,因为二级缓存数据存储介质多种多样,不一定只存在内存中,有可能存在硬盘中,如果我们再取出这个缓存的话,就需要反序列化。所以 MyBatis 的所有 pojo 类都要去实现 Serializable 序列化接口。 ## 七、二级缓存实验 **7.1 实验 1** **测试二级缓存与 SqlSession 无关** ``` @Test public void secondLevelCache() { SqlSession sqlSession1 = sqlSessionFactory.openSession(); SqlSession sqlSession2 = sqlSessionFactory.openSession(); UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class); UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class); // 第一次查询id为1的用户 User user1 = userMapper1.findUserById(1); sqlSession1.close(); // 清空一级缓存 System.out.println(user1); // 第二次查询id为1的用户 User user2 = userMapper2.findUserById(1); System.out.println(user2); System.out.println(user1 == user2); } ``` 控制台日志输出:  第一次查询时,将查询结果放入缓存中,第二次查询,即使 sqlSession1.close(); 清空了一级缓存,第二次查询依然不发出 sql 语句。 这里的你可能有个疑问,这里不是二级缓存了吗?怎么 user1 与 user2 不相等? 这是因为二级缓存的是数据,并不是对象。而 user1 与 user2 是两个对象,所以地址值当然也不想等。 **7.2 实验 2** **测试执行 commit(),二级缓存数据清空。** ``` @Test public void secondLevelCacheOfUpdate() { SqlSession sqlSession1 = sqlSessionFactory.openSession(); SqlSession sqlSession2 = sqlSessionFactory.openSession(); SqlSession sqlSession3 = sqlSessionFactory.openSession(); UserMapper userMapper1 = sqlSession1.getMapper(UserMapper.class); UserMapper userMapper2 = sqlSession2.getMapper(UserMapper.class); UserMapper userMapper3 = sqlSession3.getMapper(UserMapper.class); // 第一次查询id为1的用户 User user1 = userMapper1.findUserById(1); sqlSession1.close(); // 清空一级缓存 User user = new User(); user.setId(3); user.setUsername("edgar"); userMapper3.updateUser(user); sqlSession3.commit(); // 第二次查询id为1的用户 User user2 = userMapper2.findUserById(1); sqlSession2.close(); System.out.println(user1 == user2); } ``` 控制台日志输出: 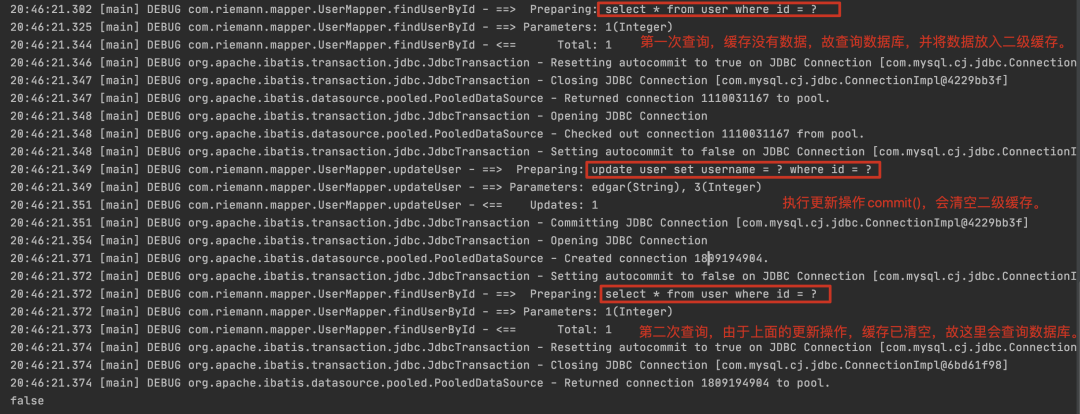 我们可以看到,在 sqlSession3 更新数据库,并提交事务后,sqlsession2 的 UserMapper namespace 下的查询走了数据库,没有走 Cache。 **7.3 实验 3** 验证 MyBatis 的二级缓存不适应用于映射文件中存在多表查询的情况。 通常我们会为每个单表创建单独的映射文件,由于 MyBatis 的二级缓存是基于 namespace 的,多表查询语句所在的 namspace 无法感应到其他 namespace 中的语句对多表查询中涉及的表进行的修改,引发脏数据问题。 为了解决实验 3 的问题呢,可以使用 Cache ref,让 OrderMapper 引用 UserMapper 命名空间,这样两个映射文件对应的 SQL 操作都使用的是同一块缓存了。 不过这样做的后果是,缓存的粒度变粗了,多个 Mapper namespace 下的所有操作都会对缓存使用造成影响。 这里老周就不代码演示了,有没有感觉很鸡肋,而且不熟用二级缓存的话,像这种多表查询的,很容易造成脏读数据不一致,这在线上的话是致命的。 **7.4 useCache 和 flushCache** useCache 是用来设置是否禁用二级缓存的,在 statement 中设置 useCache="false",可以禁用当前 select 语句的二级缓存,即每次都会去数据库查询。如下: ``` <select id="findAll" resultMap="userMap" useCache="false"> select * from user u left join orders o on u.id = o.uid </select> ``` 设置 statement 配置中的 flushCache=“true” 属性,默认情况下为 true,即刷新缓存,一般执行完 commit 操作都需要刷新缓存,flushCache=“true” 表示刷新缓存,这样可以避免增删改操作而导致的脏读问题。默认不要配置,如下: ``` <select id="findAll" resultMap="userMap" useCache="false" flushCache="true"> select * from user u left join orders o on u.id = o.uid </select> ``` ## 八、二级缓存源码分析 MyBatis 二级缓存的工作流程和前文提到的一级缓存类似,只是在一级缓存处理前,用 CachingExecutor 装饰了 BaseExecutor 的子类,在委托具体职责给 delegate 之前,实现了二级缓存的查询和写入功能,具体类关系图如下图所示。  源码分析从 CachingExecutor 的 query 方法展开,首先会从 MappedStatement 中获得在配置初始化时赋予的 Cache。 ``` public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException { Cache cache = ms.getCache(); // 首先会从 MappedStatement 中获得在配置初始化时赋予的 Cache if (cache != null) { this.flushCacheIfRequired(ms); if (ms.isUseCache() && resultHandler == null) { this.ensureNoOutParams(ms, parameterObject, boundSql); List<E> list = (List)this.tcm.getObject(cache, key); if (list == null) { list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); this.tcm.putObject(cache, key, list); } return list; } } return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); } ``` 本质上是装饰器模式的使用,具体的装饰链是: > SynchronizedCache -> LoggingCache -> SerializedCache -> LruCache -> PerpetualCache。  以下是具体这些 Cache 实现类的介绍,他们的组合为 Cache 赋予了不同的能力。 - `SynchronizedCache`:同步 Cache,实现比较简单,直接使用 synchronized 修饰方法。 - `LoggingCache`:日志功能,装饰类,用于记录缓存的命中率,如果开启了 DEBUG 模式,则会输出命中率日志。 - `SerializedCache`:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的 Copy,用于保存线程安全。 - `LruCache`:采用了 LRU 算法的 Cache 实现,移除最近最少使用的 Key/Value。 - `PerpetualCache`:作为为最基础的缓存类,底层实现比较简单,直接使用了 HashMap。 然后是判断是否需要刷新缓存,也就是上面代码中的: ``` this.flushCacheIfRequired(ms); ``` 在默认的设置中 SELECT 语句不会刷新缓存,insert/update/delte 会刷新缓存。进入该方法。代码如下所示: ``` private void flushCacheIfRequired(MappedStatement ms) { Cache cache = ms.getCache(); if (cache != null && ms.isFlushCacheRequired()) { this.tcm.clear(cache); } } ``` MyBatis 的 CachingExecutor 持有了 TransactionalCacheManager,即上述代码中的 tcm。 TransactionalCacheManager 中持有了一个 Map,代码如下所示: ``` private Map<Cache, TransactionalCache> transactionalCaches = new HashMap<Cache, TransactionalCache>(); ``` 这个 Map 保存了 Cache 和用 TransactionalCache 包装后的 Cache 的映射关系。 TransactionalCache 实现了 Cache 接口,CachingExecutor 会默认使用他包装初始生成的 Cache,作用是如果事务提交,对缓存的操作才会生效,如果事务回滚或者不提交事务,则不对缓存产生影响。 在 TransactionalCache 的 clear,有以下两句。清空了需要在提交时加入缓存的列表,同时设定提交时清空缓存,代码如下所示: ``` @Override public void clear() { clearOnCommit = true; entriesToAddOnCommit.clear(); } ``` CachingExecutor#query 继续往下走,ensureNoOutParams 主要是用来处理存储过程的,暂时不用考虑。 ``` if (ms.isUseCache() && resultHandler == null) { ensureNoOutParams(ms, parameterObject, boundSql); ... } ``` 之后会尝试从 tcm 中获取缓存的列表。 ``` List<E> list = (List<E>) tcm.getObject(cache, key); ``` 在 getObject 方法中,会把获取值的职责一路传递,最终到 PerpetualCache。如果没有查到,会把 key 加入 Miss 集合,这个主要是为了统计命中率。 ``` // TransactionalCache#getObject public Object getObject(Object key) { Object object = this.delegate.getObject(key); if (object == null) { this.entriesMissedInCache.add(key); } return this.clearOnCommit ? null : object; } ``` CachingExecutor 继续往下走,如果查询到数据,则调用 tcm.putObject 方法,往缓存中放入值。 ``` if (list == null) { list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); this.tcm.putObject(cache, key, list); // issue #578 and #116 } ``` tcm 的 put 方法也不是直接操作缓存,只是在把这次的数据和 key 放入待提交的 Map 中。 ``` public void putObject(Cache cache, CacheKey key, Object value) { this.getTransactionalCache(cache).putObject(key, value); } public void putObject(Object key, Object object) { entriesToAddOnCommit.put(key, object); } ``` 从以上的代码分析中,我们可以明白,如果不调用 commit 方法的话,由于 TranscationalCache 的作用,并不会对二级缓存造成直接的影响。我们来看下 CachingExecutor#commit 方法: ``` public void commit(boolean required) throws SQLException { this.delegate.commit(required); this.tcm.commit(); } ``` 会把具体 commit 的职责委托给包装的 Executor。主要是看下 tcm.commit(),tcm 最终又会调用到 TrancationalCache。 ``` // TransactionalCacheManager#commit public void commit() { Iterator var1 = this.transactionalCaches.values().iterator(); while(var1.hasNext()) { TransactionalCache txCache = (TransactionalCache)var1.next(); txCache.commit(); } } // TransactionalCache#commit public void commit() { if (this.clearOnCommit) { this.delegate.clear(); } this.flushPendingEntries(); this.reset(); } ``` 看到这里的 clearOnCommit 就想起刚才 TrancationalCache 的 clear 方法设置的标志位,真正的清理 Cache 是放到这里来进行的。具体清理的职责委托给了包装的 Cache 类。之后进入 flushPendingEntries 方法。代码如下所示: ``` private void flushPendingEntries() { Iterator var1 = this.entriesToAddOnCommit.entrySet().iterator(); while(var1.hasNext()) { Entry<Object, Object> entry = (Entry)var1.next(); this.delegate.putObject(entry.getKey(), entry.getValue()); } var1 = this.entriesMissedInCache.iterator(); while(var1.hasNext()) { Object entry = var1.next(); if (!this.entriesToAddOnCommit.containsKey(entry)) { this.delegate.putObject(entry, (Object)null); } } } ``` 在 flushPendingEntries 中,将待提交的 Map 进行循环处理,委托给包装的 Cache 类,进行 putObject 的操作。 后续的查询操作会重复执行这套流程。如果是 insert|update|delete 的话,会统一进入 CachingExecutor 的 update 方法,其中调用了这个函数,代码如下所示: ``` private void flushCacheIfRequired(MappedStatement ms) ``` 在二级缓存执行流程后就会进入一级缓存的执行流程,因此不再赘述 。 ## 九、二级缓存小结 - MyBatis 的二级缓存相对于一级缓存来说,实现了 SqlSession 之间缓存数据的共享,同时粒度更加的细,能够到 namespace 级别,通过 Cache 接口实现类不同的组合,对 Cache 的可控性也更强。 - MyBatis 在多表查询时,极大可能会出现脏数据,有设计上的缺陷,安全使用二级缓存的条件比较苛刻。 - 在分布式环境下,由于默认的 MyBatis Cache 实现都是基于本地的,分布式环境下必然会出现读取到脏数据,需要使用集中式缓存将 MyBatis 的 Cache 接口实现,有一定的开发成本,直接使用 Redis、Memcached 等分布式缓存可能成本更低,安全性也更高。 ## 十、总结 本文先是介绍了 MyBatis 的缓存,MyBatis 的缓存分为一、二级缓存,一级缓存是 SqlSession 级别的缓存,二级缓存是 Mapper 级别的缓存;然后从工作流程、应用试验以及源码层面分析了 MyBatis 的一、二级缓存机制;最后对 MyBatis 的一、二级缓存做了相应的小结。 老周建议 MyBatis 的一级、二级缓存只作为 ORM 框架使用就行了,线上环境得关闭 MyBatis 的缓存机制。通过全文分析,不知道你有没有觉得 MyBatis 的缓存机制很鸡肋? 一级缓存来说对于有多个 SqlSession 或者分布式的环境下,数据库写操作会引起脏数据以及对于增删改多的操作来说,清除一级缓存会很频繁,这会导致一级缓存形同虚设。 二级缓存来说实现了 SqlSession 之间缓存数据的共享,除了跟一级缓存一样对于增删改多的操作来说,清除二级缓存会很频繁,这会导致二级缓存形同虚设;MyBatis 的二级缓存不适应用于映射文件中存在多表查询的情况,由于 MyBatis 的二级缓存是基于 namespace 的,多表查询语句所在的 namspace 无法感应到其他 namespace 中的语句对多表查询中涉及的表进行的修改,引发脏数据问题。虽然可以通过 Cache ref 来解决多表的问题,但这样做的后果是,缓存的粒度变粗了,多个 Mapper namespace 下的所有操作都会对缓存使用造成影响。 综上,生产环境要关闭 MyBatis 的缓存机制。你可能会问,老周,你说生产环境不推荐用,那为啥很多面试官很喜欢问 MyBatis 的一级、二级缓存机制呢?那你把老周这篇丢给他就好了,最后你再反问面试官,你们生产环境有用 MyBatis 的一级、二级缓存机制吗?大多数的答案要么是没用或者它自己也不知道用没用就随便那几道题来面你。如果面试官回答生产环境用了的话,那你就把这些用的弊端跟面试官交流交流。 好了深入浅出 MyBatis 的一级、二级缓存机制就到这了,我们下期再见。
LazzMan
2023年4月13日 12:22
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码