大数据工程师
常见问题
数据人必须了解的大数据中台技术架构
数据采集&传输
Flume
Logstash
Flume和Logstash对比
数据存储
Hadoop
Hbase
数据计算&查询
Hive
Spark
大数据实践
集群搭建
医疗数据分析
高校专业学科分析
互联网日志分析
本文档使用 MrDoc 发布
-
+
首页
Flume和Logstash对比
## Flume和 Logstash 对比 ### 一、概述 在某个 Logstash 的场景下,我产生了为什么不能用 Flume 代替 Logstash 的疑问,因此查阅了不少材料在这里总结,大部分都是前人的工作经验下,加了一些我自己的思考在里面,希望对大家有帮助。 大数据的数据采集工作是大数据技术中非常重要、基础的部分,数据不会平白无故地跑到你的数据平台软件中,你得用什么东西把它从现有的设备(比如服务器,路由器、交换机、防火墙、数据库等)采集过来,再传输到你的平台中,然后才会有后面更加复杂高难度的处理技术。 目前,Flume 和 Logstash 是比较主流的数据采集工具(主要用于日志采集),但是很多人还不太明白两者的区别,特别是对用户来说,具体场景使用合适的采集工具,可以大大提高效率和可靠性,并降低资源成本。 我们先来看 Logstash,然后看 Flume ### 二、一个通用的数据采集模型 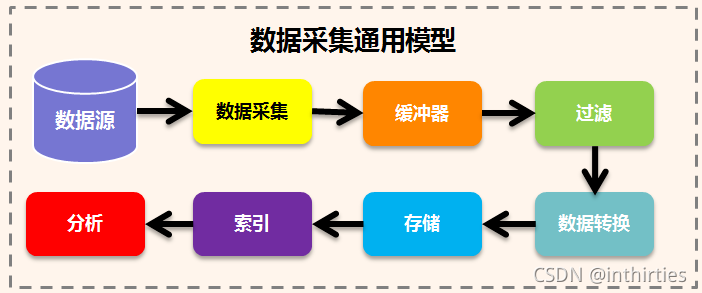 普适环境的数据采集 其中,数据采集和存储是必要的环节,其他并不一定需要。是不是很简单?本来编程其实就是模块化的东西,没有那么难。但是这毕竟只是一个粗略的通用模型,不同开源社区或者商业厂家开发的时候都会有自己的考虑和目的。我们在本文要讨论的 Flume 和 Logstash 原则上都属于数据采集这个范畴,尽管两者在技术上或多或少都自带了一些缓冲、过滤等等功能。 ### 三、Logstash Logstash 是 ELK 组件中的一个。所谓 ELK 就是指,ElasticSearch、Logstash、Kibana 这三个组件。那么为什么这三个组件要合在一起说呢?第一,这三个组件往往是配合使用的(ES 负责数据的存储和索引,Logstash 负责数据采集和过滤转换,Kibana 则负责图形界面处理);第二,这三个组件又先后被收购于 Elastic.co 公司名下。是不是很巧合?这里说个题外话,原 ELK Stack 在 5.0 版本加入 Beats(一种代理)套件后改称为 Elastic Stack,这两个词是一个意思,只不过因为增加了 Beats 代理工具,改了个名字。 Logstash 诞生于 2009 年 8 有 2 日,其作者是世界著名的虚拟主机托管商 DreamHost 的运维工程师乔丹 西塞(Jordan Sissel)。Logstash 的开发很早,对比一下,Scribed 诞生于 2008 年,Flume 诞生于 2010 年,Graylog2 诞生于 2010 年,Fluentd 诞生于 2011 年。2013 年,Logstash 被 ElasticSearch 公司收购。这里顺便提一句,Logstash 是乔丹的作品,所以带着独特的个人性格,这一点不像 Facebook 的 Scribe,Apache 的 Flume 开源基金项目。 Logstash 的设计非常规范,有三个组件,其分工如下: - 1、Shipper 负责日志收集。职责是监控本地日志文件的变化,并输出到 Redis 缓存起来; - 2、Broker 可以看作是日志集线器,可以连接多个 Shipper 和多个 Indexer; - 3、Indexer 负责日志存储。在这个架构中会从 Redis 接收日志,写入到本地文件。 这里要说明,因为架构比较灵活,如果不想用 Logstash 的存储,也可以对接到 Elasticsearch,这也就是前面所说的 ELK 的套路了。 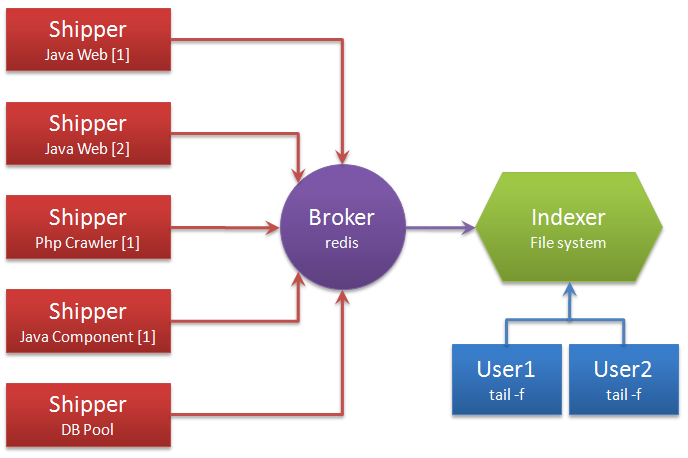 如果继续细分,Logstash 也可以这么解剖来看 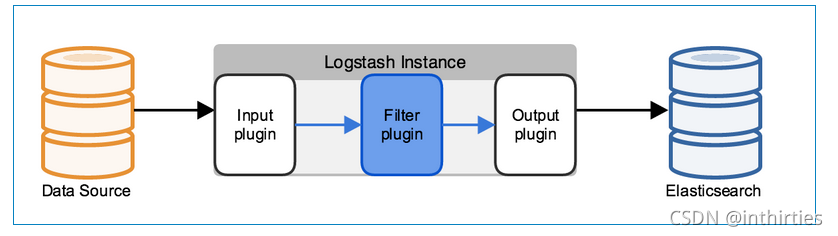 Logstash 三个工作阶段 貌似到这里。。。好像就讲完了。。。读者朋友们不要骂我,因为 Logstash 就是这么简约,全部将代码集成,程序员不需要关心里面是如何运转的。 Logstash 最值得一提的是,在 Filter plugin 部分具有比较完备的功能,比如 grok,能通过正则解析和结构化任何文本,Grok 目前是**Logstash 最好的方式对非结构化日志数据解析成结构化和可查询化**。此外,Logstash 还可以重命名、删除、替换和修改事件字段,当然也包括完全丢弃事件,如 debug 事件。还有很多的复杂功能供程序员自己选择,**你会发现这些功能 Flume 是绝对没有**(以它的轻量级线程也是不可能做到的)。当然,在 input 和 output 两个插件部分也具有非常多类似的可选择性功能,程序员可以自由选择,这一点跟 Flume 是比较相似的。 ### 四、Flume Logstash 因为集成化设计,所以理解起来其实不难。现在我们讲讲 Flume,这块内容就有点多了。 #### 1、Flume OG 最早 Flume 是由 Cloudrea 开发的日志收集系统,初始的发行版本叫做 Flume OG(就是 original generation 的意思),作为开源工具,一经公布,其实是很受关注的一套工具,但是后面随着功能的拓展,暴露出代码工程臃肿、核心组件设计不合理、核心配置不标准等各种缺点。尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象特别严重。我们来看看 Flume OG 到底有什么问题。 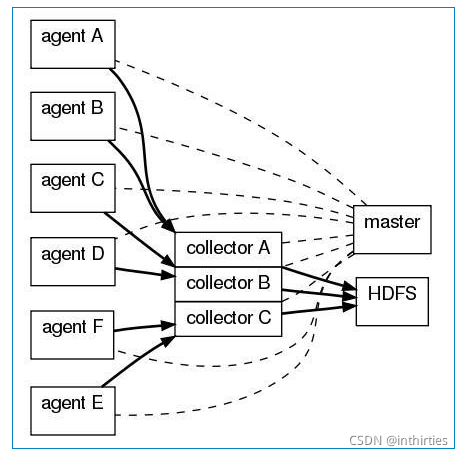 Flume OG 架构图 直到现在,你在网络上搜索 Flume 相关资料的时候还会经常出现 Flume OG 的结构图,这对新人来说是很不友好的,很容易引起误导,请读者朋友们一定要注意!我们可以看到 Flume OG 有三种角色的节点:代理节点(agent)、收集节点(collector)、主节点(master)。 流程理解起来也并不困难:agent 从各个数据源收集日志数据,将收集到的数据集中到 collector,然后由收集节点汇总存入 hdfs。master 负责管理 agent,collector 的活动。agent、collector 都称为 node,node 的角色根据配置的不同分为 logical node(逻辑节点)、physical node(物理节点)。对 logical nodes 和 physical nodes 的区分、配置、使用一直以来都是使用者最头疼的地方。 Flume OG 中节点的构成 agent、collector 由 source、sink 组成,代表在当前节点数据是从 source 传送到 sink。 就算是外行人,看到这里也觉得很头大,这尼玛是谁设计出来的破玩意? 各种问题的暴露,迫使开发者痛下决心,抛弃原有的设计理念,彻底重写 Flume。于是在 2011 年 10 月 22 号,Cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation 下一代的意思);改动的另一原因是将 Flume 纳入 apache 旗下,Cloudera Flume 改名为 Apache Flume,所以现在 Flume 已经是 Apache ETL 工具集中的一员。 这里说个题外话,大家都知道,通常情况下大公司,特别是大型 IT 公司是比较排斥使用一些不稳定的新技术的,也不喜欢频繁变换技术,这很简单,因为变化很容易导致意外。举个例子,Linux 发展了二十多年了,大部分公司都在使用 RedHat、CentOS 和 Ubuntu 这类旨在提供稳定、兼容好的版本,如果你看到一家公司用的是 Linux 新内核,那多半是一家新公司,需要用一些新技术在竞争中处于上风。 #### 2、Flume NG 好,了解了一些历史背景,现在我们可以放上 Flume NG 的结构图了 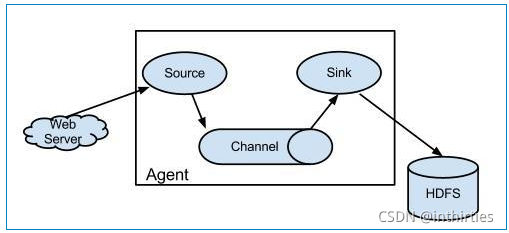 Flume NG 结构图 卧槽,是不是很简单?!对比一下 OG 的结构,外行人都会惊叹:so easy! 这次开发者吸取了 OG 的血淋林教训,将最核心的几块部分做了改动: - 1、NG 只有一种角色的节点:代理节点(agent),而不是像 OG 那么多角色; - 2、没有 collector,master 节点。这是核心组件最核心的变化; - 3、去除了 physical nodes、logical nodes 的概念和相关内容; - 4、agent 节点的组成也发生了变化,NG agent 由 source、sink、channel 组成。 那么这么做有什么好处呢?简单概括有这么三点: - 1、NG 简化核心组件,移除了 OG 版本代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点,使得数据流的配置变得更简单合理,这是比较直观的一个改进点; - 2、NG 脱离了 Flume 稳定性对 zookeeper 的依赖。在早期的 OG 版本中,Flume 的使用稳定性依赖 zookeeper。它需要 zookeeper 对其多类节点(agent、collector、master)的工作进行管理,尤其是在集群中配置多个 master 的情况下。当然,OG 也可以用内存的方式管理各类节点的配置信息,但是需要用户能够忍受在机器出现故障时配置信息出现丢失。所以说 OG 的稳定行使用是依赖 zookeeper 的。 - 3、NG 版本对用户要求大大降低:安装过程除了 java 无需配置复杂的 Flume 相关属性,也无需搭建 zookeeper 集群,安装过程几乎零工作量。 有人很不解,怎么突然冒出来一个 Zookeeper 这个概念,这是个啥玩意?简单的说,Zookeeper 是针对大型分布式系统的可靠协调系统,适用于有多类角色集群管理。你可以把它理解为整个 Hadoop 的总管家,负责整个系统所有组件之间的协调工作管理。这个组件平时很不起眼,但非常重要。好比一支篮球队,五个队员个个都是巨星,所以我们平时都习惯关注这五个人,但是整个球队的获胜缺不了教练的协调组织、战术安排,Zookeeper 就好比是整个 Hadoop 系统的教练。比喻虽然有些生硬,只是想说明 Zookeeper 的重要性,也侧面说明 NG 在摆脱了 Zookeeper 的依赖后变得更加轻便,灵活。 说个题外话,OG 版本的使用文档有 90 多页,而 NG 只用 20 多页的内容就完成了新版 Flume 的使用说明。可见在科学研究领域,人类总是在追求真理,而真理总是可以用最简单的语言描述出来。 到这里差不多 Flume 就讲的差不多了,因为这个线程工具从原理上讲真的很简单,三段式的结构:源(Source 输入)——存储(Channel 管道)——出口(Sink 目标输出)。但也因为涉及到这三个结构,所以做配置就比较复杂,这里举个例子,我们看看 Flume 在一些场景下是如何搭建布置的。 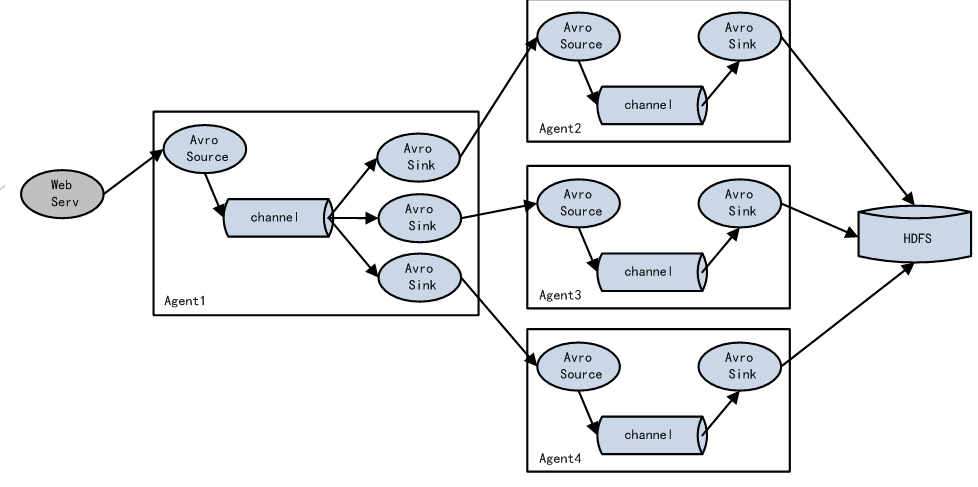 > Flume 集群部署 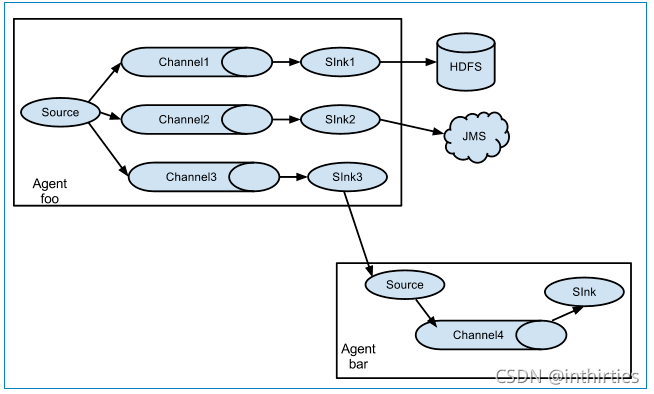 这里要纠正几个很多初学 Flume 朋友们的误区。首先,Flume 已经可以支持一个 Agent 中有多个不同类型的 channel 和 sink,**我们可以选择把 Source 的数据复制,分发给不同的目的端口**,比如: > Flume 的多重复用 其次,Flume 还自带了分区和拦截器功能,因此不是像很多实验者认为的没有过滤功能(当然我承认 Flume 的过滤功能比较弱)。 读者可能会隐约感觉到,**Flume 在集群中最擅长的事情就是做路由了**,因为每一个 Flume Agent 相连就构成了一条链路,**这也是众多采集工具中 Flume 非常出色的亮点**。但是也正因为如此,如果有一个 Flume Agent 出了问题,那么整个链路也会出现问题,所以在集群中需要设计分层架构等来实现冗余备份。但这么一来,配置又会变得很麻烦。 ### 五、对比 把 Logstash 和 Flume 都讲完了,我们最后可以对比总结一下了。 首先从结构对比,我们会惊人的发现,两者是多么的相似!Logstash 的 Shipper、Broker、Indexer 分别和 Flume 的 Source、Channel、Sink 各自对应!只不过是 Logstash 集成了,Broker 可以不需要,而 Flume 需要单独配置,且缺一不可,但这再一次说明了计算机的设计思想都是通用的!只是实现方式会不同而已。 从程序员的角度来说,上文也提到过了,Flume 是真的很繁琐,你需要分别作 source、channel、sink 的手工配置,而且涉及到复杂的数据采集环境,你可能还要做多个配置,这在上面提过了,反过来说 Logstash 的配置就非常简洁清晰,三个部分的属性都定义好了,程序员自己去选择就行,就算没有,也可以自行开发插件,非常方便。当然了,Flume 的插件也很多,但 Channel 就只有内存和文件这两种(其实现在不止了,但常用的也就两种)。读者可以看得出来,两者其实配置都是非常灵活的,只不过看场景取舍罢了。 其实从作者和历史背景来看,两者最初的设计目的就不太一样。**Flume 本身最初设计的目的是为了把数据传入 HDFS 中**(并不是为了采集日志而设计,这和 Logstash 有根本的区别),所以理所应当侧重于数据的传输,程序员要非常清楚整个数据的路由,并且比 Logstash 还多了一个可靠性策略,上文中的 channel 就是用于持久化目的,数据除非确认传输到下一位置了,否则不会删除,这一步是通过事务来控制的,这样的设计使得可靠性非常好。相反,Logstash 则明显侧重对数据的预处理,因为日志的字段需要大量的预处理,为解析做铺垫。 回过来看我当初为什么先讲 Logstash 然后讲 Flume?这里面有几个考虑,其一:Logstash 其实更有点像通用的模型,所以对新人来说理解起来更简单,而 Flume 这样轻量级的线程,可能有一定的计算机编程基础理解起来更好;其二:目前大部分的情况下,Logstash 用的更加多,这个数据我自己没有统计过,但是**根据经验判断,Logstash 可以和 ELK 其他组件配合使用,开发、应用都会简单很多,技术成熟,使用场景广泛。相反 Flume 组件就需要和其他很多工具配合使用,场景的针对性会比较强**,更不用提 Flume 的配置过于繁琐复杂了。 最后总结下来,我们可以这么理解他们的区别:Logstash 就像是买来的台式机,主板、电源、硬盘,机箱(Logstash)把里面的东西全部装好了,你可以直接用,当然也可以自己组装修改;Flume 就像提供给你一套完整的主板,电源、硬盘,Flume 没有打包,只是像说明书一样指导你如何组装,才能运行的起来。
LazzMan
2023年10月25日 20:13
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
PDF文档(打印)
分享
链接
类型
密码
更新密码